用户收到的信息量如同波涛汹涌,如何高效处理这些庞大资料成为大家关注的难题。机器学习技术为解决这一挑战提供了可能的方法,接下来,我们将探讨其具体的解决途径。
优化情报分类

在处理用户对道路信息的反馈时,这涉及到从最初的按规则分类到后续处理的复杂过程,实际上是一个涉及多级分类的文本分类任务。尽管每个分类级别都有所不同,但模型的结构是可以重复使用的,只需进行一些针对性的调整。这个过程就像是为杂乱无章的数据构建一个有序的框架,首先将它们进行初步的区分。此外,为了提升模型的表现,我们尝试了双向LSTM模型和不同的填充方法,尽管这些方法在情报识别上的效果差异并不显著,但它们代表了我们对技术探索的积极态度。
面对海量的数据,采用重复使用的模型结构可以减少资源消耗和时间成本。比如,在处理某个区域的道路数据时,若每一条反馈信息都从头开始分析,那将是一项庞大的工作。但若运用复用技术,就能迅速识别各类信息,为后续工作奠定基础。

情报识别的探索
情报识别涉及对文本进行多类别划分。这一过程与分类情报的逻辑相近,但也有其特别之处。在此阶段,我们尝试了多种方法,旨在提高数据处理的精确度和效率。由于不同用户提问的方式各异,且分布较为均匀,这给优化工作带来了不小的挑战。

在应对不同城市的交通道路用户意见时,表达方式和关注点差异显著。比如在北京,人们更关注路线调整对上下班族出行的影响;而在旅游城市,人们则更多地谈论这给游客带来的不便。因此,必须针对这些具体问题持续寻找最合适的解决办法。
去无效流程的必要性
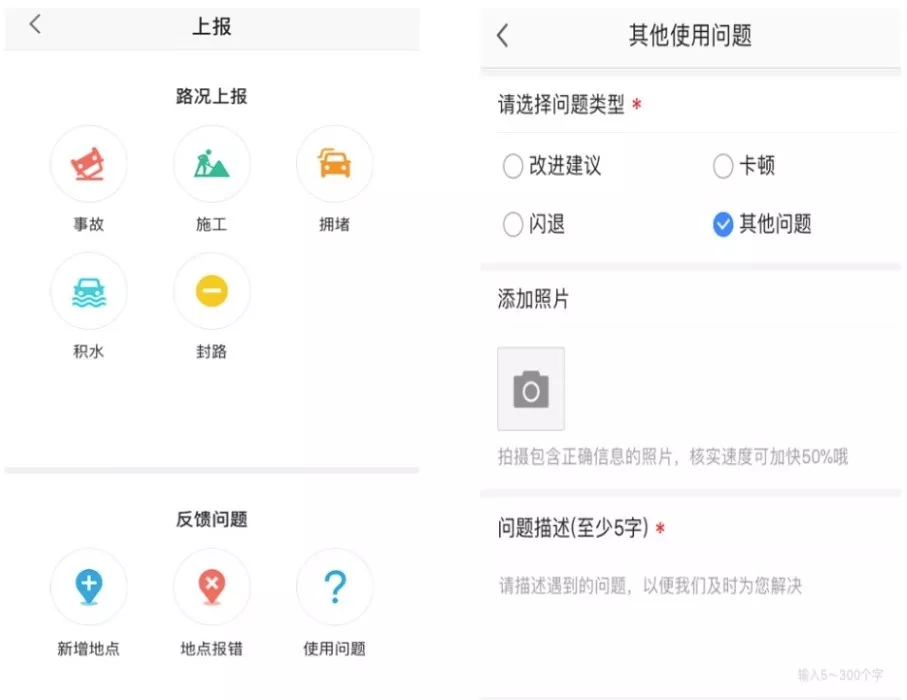
业务流程的第一步,剔除无效信息十分关键。对用户反馈进行有效与无效的区分,并分别设立处理流程,这完全符合实际需要。若不处理无效信息,它们将扰乱数据处理的全过程,进而降低效率。

在某段时间内,我们会收到很多与道路无关的反馈,这些内容要么是无关紧要的骚扰,要么是明显错误的描述。当这些无效信息与有用的信息掺杂在一起时,要准确识别出道路上的关键问题和具体地点,就会变得非常困难。
置信度区分的尝试
为了算法成功应用,类别内置信度的区分至关重要。我们采用了置信度模型和按类别设定阈值的策略。置信度模型有其独特方法,它以分类模型的标签输出为依据,重新划分训练集和验证集进行二分类。然而,最终按类别设定阈值因其简便快捷而脱颖而出。

以城市道路维修的反馈为例,若误用置信度模型或阈值设置有误,可能会导致一些应立即处理的关键信息被错误判断,进而影响道路数据的更新速度。
最终算法效果
依据高置信度内容采用自动化处理,对于低置信度内容则实施人工标注,情报识别的算法在描述准确率方面已超过96%。这一成绩充分验证了之前所采取的一系列处理手段的有效性。
实际上,在使用过程中,这种准确性确实提升了数据处理的速度和精确度。比如,在一个月内处理上万条用户反馈时,能够准确辨别出哪些是有效信息,哪些是无效信息,哪些是高置信度,哪些是低置信度,从而确保真正需要处理的道路问题能够迅速被发现。
应用成果显著
接入情报标签分类模型并完成平台搭建后,作业人员通过区分高低置信标签进行操作,效率提高了超过30%。这一成果是实实在在的,并且在工作的各个部分都有所体现。
观察整个工作流程,不论是处理城市普通道路的数据,抑或是针对新建高速公路等特殊路段的反馈,提高作业人员的效率都产生了诸多正面效应。
面对处理众多数据时的困扰,你是否感同身受?期待大家的点赞与转发,也欢迎在评论区交流心得。